
This is part of my series of posts about the PolyAnno project – more here
Getting Content
So when I started the project I definitely thought the most difficult of the annotations to handle would be the translations and so my immediate focus regarding with the transcriptions was more to just get them as quickly and efficiently so that they could be processed into translations. However this assumption was very quickly challenged.
There isn’t a way to quickly get transcriptions. They are as difficult to create and understand as translations – paleography is the study of handwriting, and interpreting what word or character a scribble on a page is supposed to be can be as controversial as interpreting how to translate a word or phrase from one language to another. This might be obvious to those more familiar with the field already but I admit that it was not something that had occurred to me until I began this project.
With this initial approach though I investigated a few different Optical Character Recognition (OCR) options (automatic transcription and machine reading of text within an image), particularly Transkribus – a popular handwriting recognition package. However the scales of identical handwriting and metadata about languages needed to be successful just wasn’t feasible with the variety and inconsistency of documents in our collection, although I could see the appeal for others.
So accepting complete user input for the transcriptions I then had to design around the problems the variety of the collection content presents for this. If the website is to accept input in potentially any language across any era then how is this input created by the user, how is it encoded, and how is this displayed? I learned a lot about how text files are actually handled whilst working on this and have consequently updated my page on web design with a text section so others can learn too.
Input
I can’t make assumptions about the kind of keyboard or other method of inputting characters the users might have available. There are two main ways of providing an input with non-latin alphabet – either by providing an alternative keyboard in browser or by converting the input from whatever combination of popular latin-alphabet characters into other Unicode characters, code known as an Input Method Editor (IME).
I researched how other websites implemented options, I looked at how Wikipedia allows special characters, and the impact of Google withdrawing the free public API associated with Translate.
To enable maximum access, or at least to enable future AB type testing I made the decision to try and incorporate both into the package development. This eventually led to the development of a whole separate package called All The Unicode, as I believed that others might find the combined functionality of use independently from the PolyAnno project – more information on this is detailed in the later post.
Encoding
The manner of how a character is stored digitally, in binary format, is defined by the international standards outlined by the Unicode Consortium, an extension and more complete mapping than the original ASCII alphabet.
Even if a website has the relevant Unicode character encoded within the HTML objects, it needs to be maintained as the information moves around. I was surprised by the slow development in this field, as someone who has only consistently needed to communicate digitally in the latin alphabet characters encoded in the original binary standard of ASCII, I had always naively assumed that other characters were simply added on to the standard at later dates. The truth was more complex – no real standards for encoding other characters were really agreed upon between companies and countries until the implementation of the Unicode consortium within the last decade. A good document I found introducing these topics and their technical consequences here.
What that means is that anyone with a device or operating system before a certain time (depending on what device and OS it is) may encode the binary that Unicode decides in the package and browser (that I am going to reasonably assume to use Unicode here), but then when it re-interprets the binary back into characters, it will do so using the non-Unicode mapping which, if it allocates something different to that particular binary combination, will produce a completely different character. Apparently this was a typical feature of the early internet when there were dozens of different ways of interpreting non-ASCII binary for Japanese characters, and the Greek alphabet etc.
The only real method of addressing this problem is to build in detection of non-Unicode systems in use, and then allow for alternative encodings but this is very cumbersome and for the infrequency of it hopefully happening, I made the decision to acknowledge that this could cause potential issues for users but incorporate no redesign for it.
Display
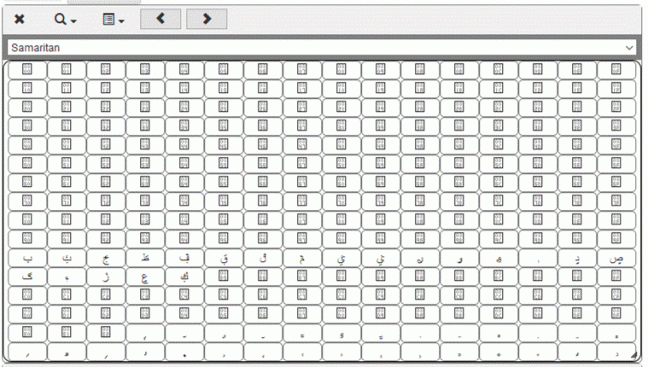
When a computer identifies the Unicode character to display, it searches through the font-family allocated by the CSS for how to display it. If there is no corresponding glyph, the actual font image for that character, then it goes to the fallback fonts but if none of them can display it then they show the “.nodef” or glyph for a character undefined in that font – normally a blank square, commonly known as “no tofu“.
To minimise the no tofus across the characters used in the website I chose to use the font packages that had the largest Unicode coverage, Google’s Noto fonts. For more reading about this project, NPR wrote a good overview here.
But to also distinguish between the remaining Unicode characters that are simply allocated private-use and those that are unsupported by Noto, I wanted to use Last Resort font as fallback with default standard fonts beyond that.
Font packages to cover so many characters are large and different web browsers respond differently to loading fonts – some time out and go to fallback if not loaded within their allocated limits, other wait until all fonts have loaded in the page before displaying anything. Either way delaying the fonts loading is not particularly great UI design and so I needed to develop a method with which to ideally selective load the fonts or at least to minimise the effects of the loading. I’m afraid to say that I was in the process of investigating these design options when I finished last summer so no definitve answers were found.
Next Up: Translation
This is part of my series of posts about the PolyAnno project – more here
