

This is part of my series of posts about the PolyAnno project – more here
Qualifications vs Wisdom of the Crowd?
The methodology by which we verify which transcriptions and translations are “most correct” was/is a huge design problem. Leaving aside the more in depth discussions about defining correct, crowd sourcing projects appeared to take two main approaches to identifying the “better” results:
- Identifying and weighting “expertise” – users who are more qualified or vetted are provided with more influence in ratings or decisions
- The power of numbers – letting individual objects differentiate themselves purely by the sheer number of supporters amongst the crowd relative to the lesser results
The biggest problem with the expertise option is deciding how to determine this qualification, something more obvious in some design contexts than others. I discussed this with colleagues at the University of Edinburgh but also noted with interest the discussions from the Annotation conference about this matter generically. However, given the difficulties of doing this within the fields of transcription and translation generally, the conclusion was reached to avoid this route if possible.
That leaves the more simple power of numbers option. More simple in premise, the largest number of ‘votes’ or equivalent wins, but more difficult to implement because it needs lots of numbers to work. And my research earlier found that most projects of this nature struggle to get anything close to this. No pressure then, but this website needs to really build and keep its users to actually work…
Linguistic and Shape Problems
The most significant problem to address with the variability and unpredictable nature of the texts was how to break up the text into segments that could be voted on? Leaflet Draw gives the users free reign to enclose any possible region of text on an image in a vector in order to label it with a transcription or translation but what if people only disagree with a smaller section within that? Do we ask users to draw a vector for each letter individually? By word or sentence? Can we provide information within the JSON files to inform the code of the nature of that segment?




After lots of discussion, ideas, and development, I chose to allow users to draw whatever shape they chose an any previously ‘untouched’ section of image (coordinates neither within nor overlapping with any other vector).

Then someone could add an initial transcription and translation for that section of image, whatever length of text.

If some of that is disputed however, then the text in writing form (as opposed to the image section displaying the text) of that section must be opened up. Then the fragment of the text, whether transcription or translation, in dispute must be highlighted, opening a menu to allow for a new alternative to be suggested.
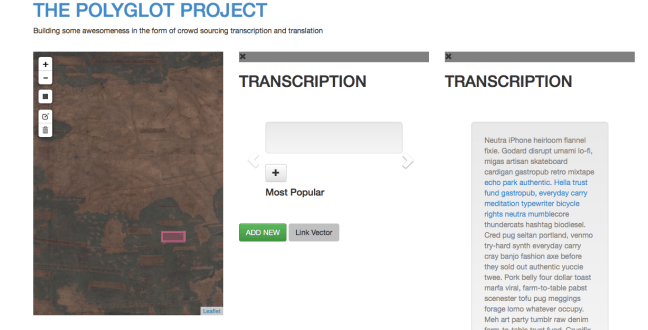

This alternative subsection is now considered a “child” fragment of the original “parent” text. A text could have several children fragments if multiple different sections are highlighted and alternatives offered.
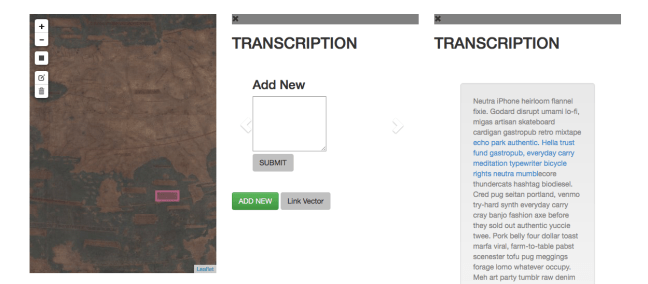
A child section can be opened up and displayed separately to the parent section. When a child fragment is displayed it is shown as a carousel, showing each alternative proposed and with an option to add another.
Each alternative for that child section can be voted on within that display.
The top voted text for that fragment is highlighted within the carousel (currently just with a different coloured panel behind it) and most importantly, sits in that section of the parent text. So if the top voted version changes, the parent text updates to reflect this.
What if the parent text is actually a child of another text?
If the user tries to draw a vector around and including other smaller vectors, then they are asked to put the existing child texts in sequential order after finishing drawing the vector. Gaps between those existing sections can be highlighted to offer alternatives (to the nothing currently there) to connect. Yes, this does raise the problem of leaving no opportunity for the ordering of children sections to be disputed after that original placement but I never said this plan was perfect, shhhhhh….
Yes, you can highlight alternatives and make children of children fragment versions. But hopefully the crowd sourcing and niche nature of this application will mean that users are too invested to troll that side of things much.
Visually, to make things easier to understand, I built some Javascript hover events to highlight the related parts simultaneously when they are open – so if you hover the cursor over a transcription section then the corresponding vector and translation will all highlight in the same colour if they are open on the page too.
What if someone tries to draw inside an existing shape and start a new family tree independent of the existing ones?
It cannot be done! If you try and draw a shape inside an existing one then it will not save the new shape but will prompt you to open the parent shape’s texts to look at sub sections in text format.
Could it be simpler?
Other existing transcription crowd sourcing tools simplify matters by restricting vector shapes or alignments (so you can always assume text order by left to right, top to bottom) but hahaha, the PolyAnno project is supposed to be working with ANY MANUSCRIPT and so you cannot make that assumption and more freedom is necessary.



Database and Code Structure Design
WARNING: Lots of code copied and pasted in this sub-section.
Storing Textual Position
In compliance with standards as well as ease of development use, the children fragments are marked out in the parent texts by marking them up as HTML span objects within the text. This means they are not necessarily visible when viewing the whole parent text (and you can copy and paste as simple text without the HTML) but the relative position is consistent, irrespective of potentially changing child text size, and the child can be treated as an object to be handled on the front end.
Text JSON Files
Within the Mongoose Schema, the transcriptions and translations store a field simply naming the parent transcription or translation as a string, then the children below as an array of the different fragments, each partnered with an id.
"parent": {
type: String
},
"children": [{
"id": {
type: String
},
"fragments": [{
"id": {
type: String
},
"votesUp": {
type: Number
},
"rank": {
type: Number
}
}]
}],
Each text JSON file can then be handled one of several ways:
- Create new basic transcription or translation from an image shape (blank child and parent array).
- Create new image shape containing existing shapes with transcriptions and/or translations (inserting the previous parent texts as children in the new array, and updating the parent fields).
- Update a transcription or translation to add a new child fragment where there were previously none (new fragment with id, and a single version with an id, vote, and rank inside it).
- Add a new version of an existing fragment (new id, vote, and rank within an existing fragment array).
- Voting on a fragment version (increasing and/or decreasing the vote number, which will correspondingly adjust ranking).
- Updating the top-voted fragment version (replacing the text in the parent fragment with the top-voted version if changed when voting occurs).
Updating To Add New Child Fragment
This is done through the following sections of code:
var newChildrenArray = newChildrenChecking(transcription.children, req.body.children);
if ( ( setup.isUseless(transcription.children) == false) && (setup.isUseless(newChildrenArray[0]) == false )
&& (newChildrenArray[0] != -1) ) {
transcription.children[newChildrenArray[0]].fragments.addToSet(newChildrenArray[1]);
}
else if ( ( setup.isUseless(transcription.children) == false) && (setup.isUseless(newChildrenArray[0]) == false )
&& (newChildrenArray[0] == -1) && (newChildrenArray[1] != -1) ) {
transcription.children.addToSet(newChildrenArray[1]);
};
var newFragmentObject = function(theID, theRank) {
return {
"id": theID,
"votesUp": 0,
"votesDown": 0,
"rank": theRank
};
};
var newLocationObject = function(theID, theFragments) {
return {
"id": theID,
"fragments": theFragments
};
};
var newChildrenLocationArray = function(oldChildren, newChildren) {
var newFragmentChild = newFragmentObject(newChildren.fragments[0].id, 0);
var newLocation = newLocationObject(newChildren.id, [ newFragmentChild ] );
return [-1, newLocation];
};
var newChildrenChecking = function(oldChildren, newChildren) {
if ( (typeof newChildren == 'undefined' || newChildren == null) || (typeof newChildren[0] == 'undefined' || newChildren[0] == null) ){
return [-1,-1];
}
else {
return oldChildrenChecking(oldChildren, newChildren[0]);
};
};
var oldChildrenChecking = function(oldChildren, newChildren) {
if (typeof oldChildren[0] != 'undefined' || oldChildren[0] != null) {
return childrenLocationChecking(oldChildren, newChildren);
}
else {
return newChildrenLocationArray(oldChildren, newChildren);
};
};
var childrenLocationChecking = function(oldChildren, newChildren) {
var theLocation = setup.fieldMatching(oldChildren, "id", newChildren.id);
if (setup.isUseless(theLocation)) {
return newChildrenLocationArray(oldChildren, newChildren);
}
else {
var thelocationIndex = oldChildren.indexOf(theLocation);
var newRank = theLocation.fragments.length;
var newFragmentChild = newFragmentObject(newChildren.fragments[0].id, newRank);
return [thelocationIndex, newFragmentChild];
};
};
Voting
Overall, this took the form of a standard Mongoose/MongoDB function with error catching:
exports.voting = function(req, res) {
var voteOn = setup.transcription_model.findOne({'id':req.body.parent});
voteOn.exec(function(err, transcription) {
if (err) {res.send(err)};
///////ALL THE IMPORTANT FUNCTIONS HERE
//JS is synchronous so this ensures that nothing is saved until whole process is done without Promises
var savingFunction = function(theNewVotes) {
transcription.save(function(err) {
if (err) {res.send(err)}
else {
res.json(theNewVotes);
};
});
};
var updateVotes = voteCheckChange(req.params.voteType);
savingFunction(updateVotes);
});
};
I then found it easier to reference the different subarrays by saving the index numbers of the relevant children and fragments within their outer arrays and so I developed a set of functions dedicated to that:
var findLocationIndex = function(loc) {
return transcription.children.indexOf(loc);
};
var theLocation = setup.fieldMatching(transcription.children, "id", req.body.children[0].id);
var thelocationIndex = findLocationIndex(theLocation);
var findFragmentIndex = function(thefrag) {
return theLocation.fragments.indexOf(thefrag);
};
var theChildDoc = setup.fieldMatching(transcription.children[thelocationIndex].fragments, "id", req.body.children[0].fragments[0].id);
var thefragmentIndex = findFragmentIndex(theChildDoc);
var fragmentChild = function(nIndex) {
return transcription.children[thelocationIndex].fragments[nIndex];
};
var fragmentChildByRank = function(therank) {
return setup.fieldMatching(transcription.children[thelocationIndex].fragments, "rank", therank);
};
Then I allowed the voting to be described a type “up” or “down” – this means only one vote per REST exchange but hopefully this will limit spamming ability. This could easily be changed within the code and was not my original design but there you go. Therefore a function is needed to check the vote type being sent:
var voteCheckChange = function(voteType) {
if (voteType == "up") {
transcription.children[thelocationIndex].fragments[thefragmentIndex].votesUp += 1 ; ///make into Promise setup??
return voteRankChange(1);
}
else if (voteType == "down") {
transcription.children[thelocationIndex].fragments[thefragmentIndex].votesUp -= 1 ;
return voteRankChange(-1);
};
};
Depending on the result, this increases the votesUp or votesDown fields… You may have noticed that I eventually removed the votesDown fields from the Mongoose Schema for simplicity but there are arguments to be made for allowing that functionality to be possible within the code design so I left the capability to handle them there.
Updating Rank
So the votesUp then determines the ranking given to a version relative to the others, with a rank of zero being the top-voted. I felt it important to keep rank as a separate field to the vote count as a large number of votes up (or down) could be indicative of more confidence or controversy then a simple position in a ranking, and otherwise that information could be lost.
var votingUpNow = function(theNeighbourIndex) {
rankChange(theNeighbourIndex, 1);
rankChange(thefragmentIndex, -1);
return true;
};
var votingDownNow = function(theNeighbourIndex) {
rankChange(theNeighbourIndex, -1);
rankChange(thefragmentIndex, 1);
return true;
};
var voteRankChange = function(voteNumber) {
///NOTE: the ranking is ONLY changed if the vote is now above or below the neighbour, not if now equal
var neighbourRank = theChildDoc.rank - voteNumber;
var theNeighbour = fragmentChildByRank(neighbourRank);
if ( (neighbourRank >= 0) && (theChildDoc.rank > neighbourRank) && ( theChildDoc.votesUp > theNeighbour.votesUp ) ) {
return votingUpNow( findFragmentIndex(theNeighbour) );
}
else if ( ( !setup.isUseless(fragmentChildByRank(neighbourRank)) ) && ( theChildDoc.rank < neighbourRank ) && ( theChildDoc.votesUp < theNeighbour.votesUp ) ) {
return votingDownNow( findFragmentIndex(theNeighbour) );
}
else {
return false;
};
};
var rankChangeLoopCheck = function(voteNumber) {
var shouldReload = voteRankChange(voteNumber);
if (shouldReload == false) {
return {"reloadText": false};
}
else {
do { shouldReload = voteRankChange(voteNumber); }
while ( shouldReload != false );
if ( shouldReload == false ) { reload(transcription.children[thelocationIndex].fragments[thefragmentIndex].rank) }; ///fragindex()
};
};
Updating Top-Voted Version
The following sections of code try and identify if the top-voted has changed:
var rankChange = function(indexNumber, rankChangeNumber) {
return transcription.children[thelocationIndex].fragments[indexNumber].rank += rankChangeNumber;
};
var reload = function(newChildRank) { //check to see if now highest ranking child and update the main transcription if so
if (newChildRank == 0){
transcription.text = replaceChildText(transcription.text, req.body.children[0].id, req.body.votedText, req.body.topText);
return {"reloadText": true};
}
else {
return {"reloadText": false};
};
};
And if it has then the replaceChildText function updates the relevant information.
var replaceChildText = function(oldText, spanID, newInsert, oldInsert) {
var idIndex = oldText.indexOf(spanID);
var startIndex = oldText.indexOf(oldInsert, idIndex);
var startHTML = oldText.slice(0, startIndex);
var EndIndex = startIndex + oldInsert.length;
var endHTML = oldText.substring(EndIndex);
var newText = startHTML + newInsert+ endHTML;
return newText;
};
Next: Users
This is part of my series of posts about the PolyAnno project – more here
